Der Wissenschafts‑Youtuber Cedric hat auf seinem Kanal „Doktor Whatson“ ein spannendes Video zum Thema „Wie TikTok dich manipuliert“ veröffentlicht. Er zeigt darin, wie schnell die Algorithmen einen in eine Klima‑Leugner‑Bubble ziehen können und räumt mit vielen Falschinformationen auf. Das Video ist sehr sehenswert für alle, die sich für dieses Thema interessieren hier entlang.
Nun möchte ich jedoch auf ein kleines neben-Thema eingehen, und zwar auf die Vertrauenswürdigkeit der Informationen, die von Large Language Models (LLMs) also KI-Modellen wie zum Beispiel ChatGPT generiert werden. Cedric erklärt ab ca. 9:34 Minuten:
„Künstliche Intelligenz ist erstmal nicht künstliche Intelligenz, sondern erstmal nur Machine Learning.“
Diese Aussage ist nicht ganz korrekt und für mich etwas zu stark vereinfacht. Machine Learning ist lediglich ein Teilbereich der Künstlichen Intelligenz (KI). Unter KI fallen darüber hinaus auch regelbasierte Ansätze, symbolische Systeme und weitere Methoden, die nicht auf statistischen Lernprozessen basieren. Moderne LLMs wie ChatGPT und Claude basieren auf Deep Learning, einem speziellen Teilbereich des Machine Learning, der mit neuronalen Netzwerken arbeitet und besonders komplexe Muster erkennen kann. Somit ist KI weitaus mehr als nur Machine Learning.
Anschließend sagt er:
„Aber es ist halt vor allem quasi der Durchschnitt, das ist jetzt nicht wirklich der Durchschnitt, aber so ein bisschen der Durchschnitt aus allem, was diesem Algorithmus gefeedet wurde.“
Hier möchte ich kurz ansetzen: Die Metapher vom „Durchschnitt“ greift zu kurz. Ein LLM berechnet nicht einfach einen Mittelwert, sondern erstellt für jedes potenzielle Wort eine Wahrscheinlichkeitsverteilung, also eine Art „verteilten Durchschnitt“ aus allen Inhalten, die es während des Trainings gesehen hat. Diese probabilistische Herangehensweise erklärt, warum es manchmal so wirkt, als würde das Modell aus einer Mischung von Informationen antworten.
Um das Thema etwas genauer zu beleuchten, stellt sich die Frage: Warum gibt uns beispielsweise ChatGPT bei identischen Fragestellungen unterschiedliche Antworten? Nehmen wir eine simple Frage wie: „Soll ich heute ein Eis essen?“
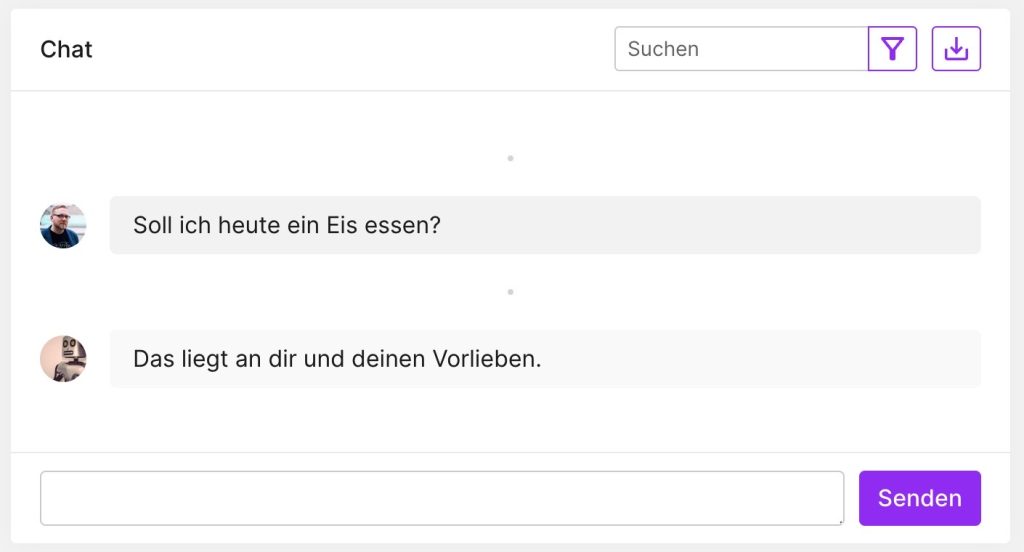
In einem Chat antwortet die KI mit „Nein“, in einem anderen mit exakt derselben Formulierung mit „Ja“ und in einem dritten Chat dann diplomatischer mit: „Das liegt an dir und deinen Vorlieben.“ Warum ändert die KI ihre Meinung? Der Grund liegt darin, dass KI‑Modelle, entgegen der weit verbreiteten Annahme, nicht-deterministisch arbeiten. Fast alle Systeme nutzen eine Form von Zufälligkeit (Temperatur), die tief in ihrem Kern implementiert ist.
Diese zufallsbasierte Elemente spielen eine wesentliche Rolle bei der Generierung von Antworten. Neben der bereits erwähnten Temperatur, die steuert, wie stark weniger wahrscheinliche Wörter einbezogen werden, kommen auch andere Sampling-Methoden zum Einsatz:
- Top-k Sampling: Hier werden nur die k wahrscheinlichsten nächsten Wörter in Betracht gezogen, was die Auswahl einschränkt und unsinnige Outputs reduziert.
- Nucleus Sampling (auch als Top-p bekannt): Diese Methode berücksichtigt nur Wörter, deren kumulative Wahrscheinlichkeit einen bestimmten Schwellenwert nicht überschreitet, was für natürlichere Texte sorgt.
Diese Techniken sorgen dafür, dass die Antworten abwechslungsreicher und für den Menschen ansprechender wirken, auch wenn dies bedeutet, dass identische Fragen in verschiedenen Chats zu unterschiedlichen Antworten führen.
Ein weiterer wichtiger Punkt ist das Phänomen der sogenannten „Halluzination„. Damit ist gemeint, dass LLMs manchmal Informationen generieren, die auf den ersten Blick plausibel wirken, in Wirklichkeit jedoch falsch oder erfunden sind. Dies liegt daran, dass diese Modelle auf statistischen Mustern basieren, die sie während des Trainings aus großen Textdatenmengen erlernt haben. Da LLMs keinen eigenen, verifizierten Wissensspeicher besitzen und nicht in Echtzeit Fakten überprüfen können, stützen sie ihre Antworten auf die aus den Trainingsdaten abgeleiteten Wahrscheinlichkeiten.
Neuere Modelle mit Reasoning-Fähigkeiten und Techniken wie RAG (Retrieval-Augmented Generation), bei denen das KI-Modell Zugriff auf externe Wissensquellen erhält, können dieses Problem reduzieren, vollständig gelöst ist es jedoch noch nicht. Besonders bei unvollständigen, widersprüchlichen oder veralteten Informationen können Halluzinationen auftreten. Dieses Problem wird aktiv in der Forschung addressiert, da es eine zentrale Herausforderung für die Zuverlässigkeit von KI-generierten Inhalten darstellt.
Die Qualität der generierten Antworten hängt zudem stark von der Qualität der Trainingsdaten ab. Werden fehlerhafte oder voreingenommene (biased) Daten verwendet, spiegelt sich das in den Ausgaben wider. Es ist also nicht nur die methodische Komplexität eines Modells, die zu Fehlinformationen führen kann, sondern auch die Qualität und Vielfalt der zugrundeliegenden Daten.
Im OpenAI‑Playground lässt sich das Prinzip der Temperatur gut beobachten: Wird sie auf 1 eingestellt, ist die Wahrscheinlichkeit hoch, dass nicht immer das statistisch wahrscheinlichste Wort gewählt wird – was zu abwechslungsreicheren, aber auch unvorhersehbareren Antworten führt. Bei einer Einstellung von 0 wird nahezu immer das wahrscheinlichste Wort gewählt. Die Standard-Temperatureinstellungen variieren je nach Modellgeneration und Anwendungsfall, wobei neuere Modelle die Temperatur sogar dynamisch an die aus dem Prompt erkennbare Nutzerintention anpassen können.
Im Video sagt Cedric auch:
„Und das sind einfach Texte aus dem Internet. Und natürlich sind da, wenn man wirklich das halbe Internet zusammen scraped, auch Klimawandel‑Leugner‑Texte dabei.“
Damit liegt er richtig: Fehlinformationen, vor allem populistische und vereinfachte Darstellungen, verbreiten sich im Internet deutlich häufiger als wissenschaftlich fundierte, oft komplexere Aufbereitungen von Informationen. Seine folgende Aussage „Garbage in, garbage out“ fasst das Problem treffend zusammen.
Nicht zuletzt werfen diese Aspekte auch ethische und praktische Fragen auf. KI‑Modelle können ein mächtiges Hilfsmittel sein, sollten aber niemals als unfehlbare Wissensquelle betrachtet werden. Es liegt in unserer Verantwortung, KI-generierte Inhalte stets kritisch zu hinterfragen und deren potenzielle Verzerrungen (Bias) sowie methodische Fallstricke zu berücksichtigen.
Zusammenfassend: Beim Einsatz von KI-Modellen sollten die generierten Antworten stets mit gesundem Skeptizismus betrachtet werden. Hier einige praktische Tipps zur Verifizierung:
- Überprüfe wichtige Informationen durch Gegenchecks mit vertrauenswürdigen Quellen
- Achte auf die Aktualität der Informationen (LLMs haben einen Wissenscutoff)
- Bei technischen oder wissenschaftlichen Aussagen: Konsultiere Fachpublikationen
- Sei besonders vorsichtig bei kontroversen Themen, wo Bias wahrscheinlicher ist
Nur durch kritisches Hinterfragen können wir die Chancen dieser Technologien nutzen und zugleich die damit verbundenen Risiken minimieren. Medienkompetenz wird immer wichtiger, und dazu gehört es auch, die Arbeitsweisen der KI-Systeme zumindest grob zu verstehen.
Jetzt mal gerne eure Meinungen und Erfahrungen zum Thema hier in die Kommentare, ich bin sehr gespannt!